


Ignotum Co-Research

Today we would like to give you more detailed insights into our project “Ignotum” with the Re-FREAM consortium – a quick refresh on why we are doing this, how we got started, failed a bit and then finally found a direction with promising results. Then, how we solidified these learnings with prototypes and what will be the next steps.

Ignotum is about confusing artificial intelligences (AIs) that are used to analyse CCTV footage. They are gaining personal information of filmed people like gender, age, emotional state and sexual preferences, some of them with very high accuracy. In recent years, these technologies are finding their ways into spaces of retail and are supposedly used for a better shopping experience. We find this development questionable and with our project, the wearer gets to choose when to be visible to these technologies.
As with most of the project in this Re-FREAM round, our co-researching phase happened mainly online: we created a digital whiteboard and had all of our meetings online.
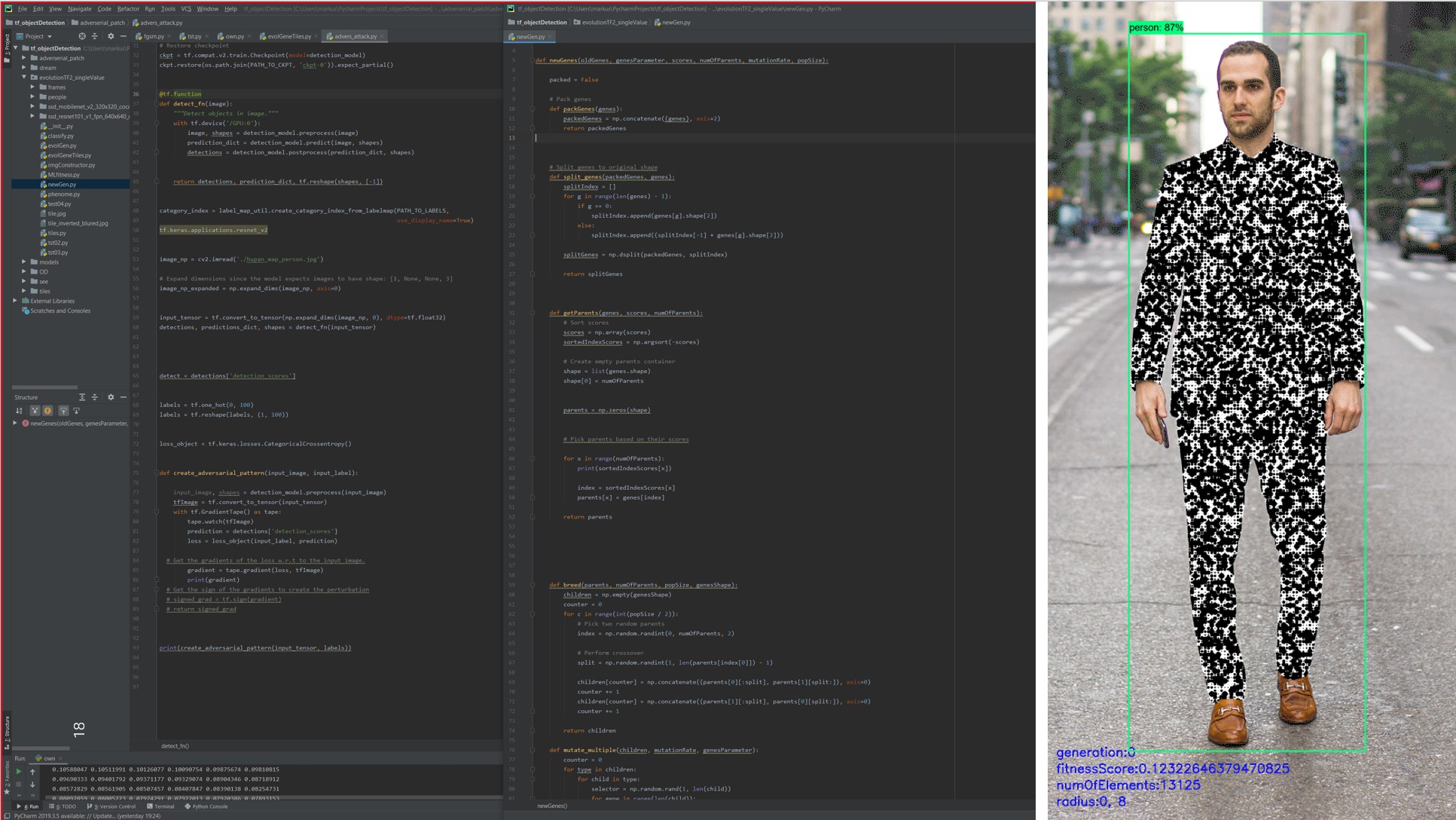
After a general research phase where we learned how these AIs are trained and work as well as what has been done in the past to “attack” these, the next step was to create our own AI-enhanced camera system, using the MobileNetV2 object detection model trained with the COCO dataset. This algorithm is allowing us to recognise 90 different objects (human beings/persons among them), attach virtual skeletons to found persons (for better tracking) and has face recognition in real-time. It is running on a Coral board and is fed by an attached HD camera.

Now we were able to point this camera at all kinds of images, like projections or screens, but also at real people, and see to which percentage the AI predicted to recognize said parameters.

The immediate practical tests we did were basically holding different kinds of samples (some provided by our technical partners) in front of our bodies to see if there were any changes in the recognition rates. Whilst it was generally quite hard to confuse the AI (unless we did a more a less full-body cover-up), active light sources like LEDs seemed to affect the numbers.

We then started to go virtual with our tests for a speedier development progression. A digital mannequin that we could “dress” with different glowing patterns, point the AI camera at (via the computer screen) and see how well they performed was created. In a long trial-and-error phase we tested hundreds of patterns. This was in the beginning quite disappointing, because all of the patterns we imagined would work, didn’t, until out of frustration we tested a simple grid pattern. That suddenly seemed to do the trick. From there we went on to find others that also worked well. To see how these were read on a moving person, a gaming engine was used to create a street environment to animate our mannequin.
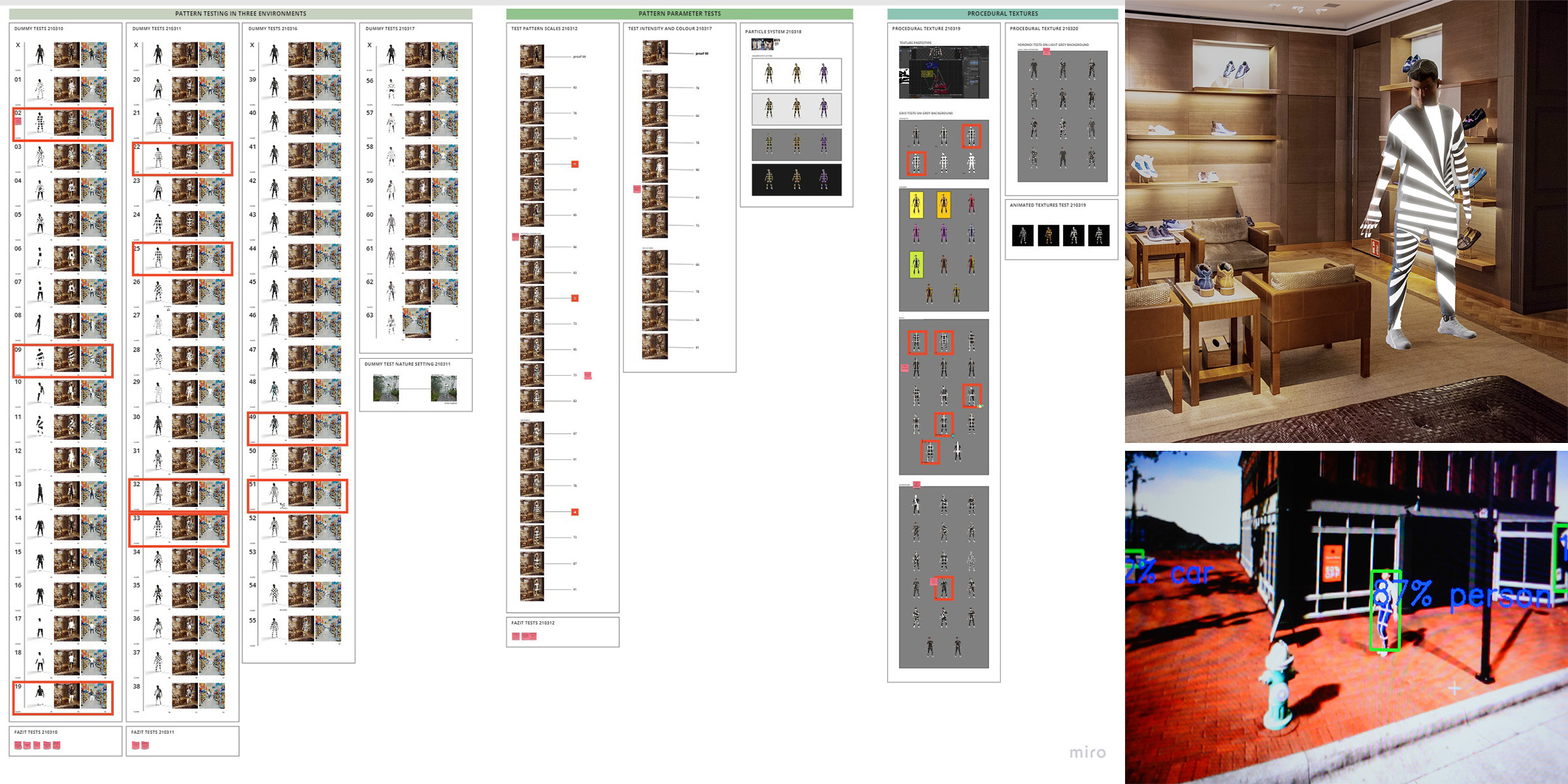
In parallel an evolutionary AI setup was created, that randomly shuffles a set modular pattern, reads the results and then mates the best options with each other to create a better performing pattern. This way we can automatically refine any pattern for its optimal performance.
We then moved to prototyping: our first ones were passively testing the final pattern, by applying sticky tape to painting overalls. These did not perform well at all. For the next ones, we utilised LED strips and here we were able to get similar results to our virtual tests.

Now we feel ready to go into the next phase – the co-creation of our final garment piece with our Re-FREAM partners: Christian Dils, Max Marwede and Robin Hoske from the Fraunhofer IZM, Naomi Kaempfer from Stratasys, Pawel Kulha from Profactor and Agnes Psikuta from Empa. We need to find an energy-efficient way of creating these light-lines, maybe with the use of light guides, we want to find a way of treating the areas in between the light-lines so they further add to the AI confusion and we have to decide on what type of garment we will concentrate on.
Author: CRE - Wolfgang
Wolfgang is communication manager for Re-FREAM and project manager at CREATIVE REGION Linz & Upper Austria.

